Shuffle过程
经常听到说spark是批处理系统,而flink能做到流处理并将批处理蕴含其中。从细节层面上来看,表现在shuffle过程中是否能否做到pipeline,因为非shuffle过程无论是Spark还是Flink都是能做到pipeline的。
何时需要shuffle?
在谈hadoop MapReduce的时候,就已经涉及的shuffle这个术语。简单来说,它是数据在Map Task和Reduce Task之间流动时的一种重新分配。类似地,在Spark中,它是ShuffleMapTask与ResultTask之间的数据流动。本质上,是否进行shuffle是由数据的依赖关系决定。
宽依赖和窄依赖
宽依赖和shuffle依赖
如何进行shuffle?
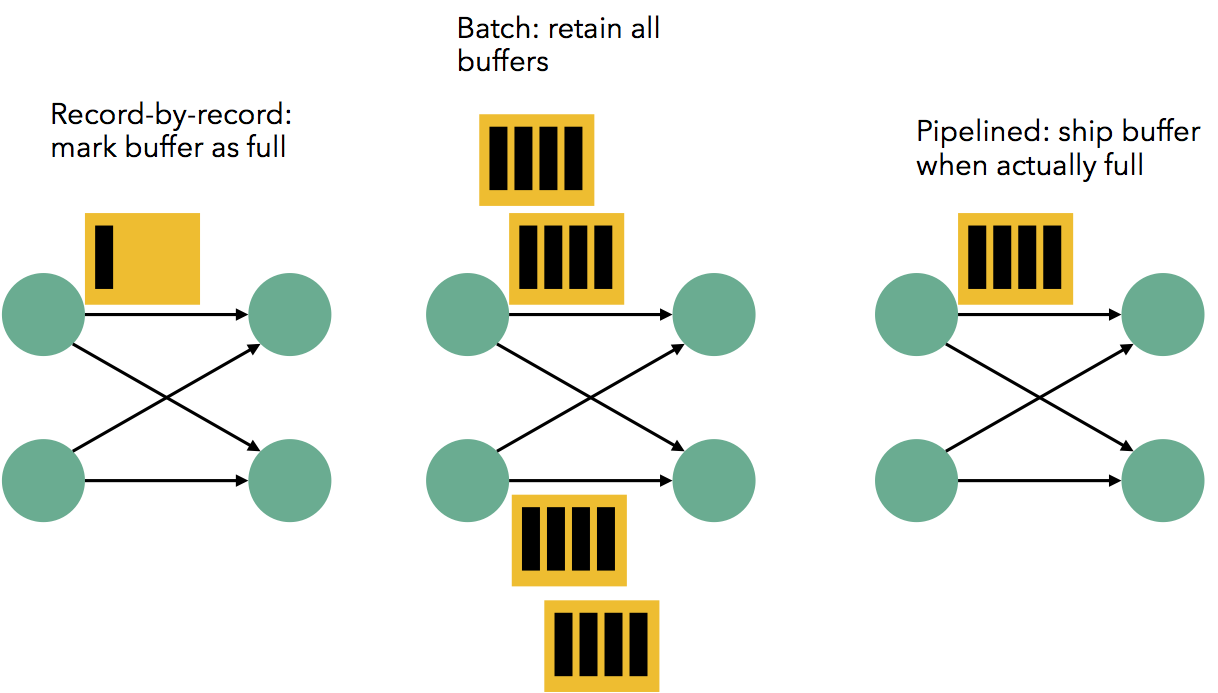 上图来自Data Artisans的博客,很形象地描述了以下三种模式:
上图来自Data Artisans的博客,很形象地描述了以下三种模式:
- 流式shuffle:左端Task每当处理完成一条数据,就序列化到缓存,并立刻传送给右端的Task。
- 批式shuffle:左端Task每当处理完成一条,序列化到缓存(缓存不够需要压到磁盘),但并不立刻传送给右端的Task,而是等到所有数据处理完成之后才传送给右端的Task。Hadoop和Spark采用的模式与此类似,不过是右端主动来取,而不是左端主动发送。
- 兼容shuffle:左端Task每当处理完成一条,序列化到缓存,等到缓存满了之后再传送给右端的Task。
理论上说,在兼容shuffle模式下,如果缓存仅容纳一条记录,那么就是流式shuffle;如果缓存无限大,那么就是批式shuffle。实际中,通过设置缓存块超时值:超时值为0,则为流式处理,超时值无限大,则为批式处理。Flink可以设置数据传输的模式。
Flink执行模式和数据交换模式
- 执行模式是一个全局的设置:包括PIPELINED, PIPELINED_FORCED, BATCH, BATCH_FORCED
- 数据交换模式是一个局部设置,可以分为一下三种情况
- FORWORD:生产者和消费者在同一个节点,此种情况显然可以pipelined,但是也是可以设置为batch方式
- SHUFFLE:生产者和消费者在不同节点,并且pipelined执行并不会引发死锁
- BREAKING:生产者和消费者在不同节点,但是pipelined执行可能会引发死锁
| 执行模式\数据交换模式 | FORWORD | SHUFFLE | BREAKING |
|---|---|---|---|
| PIPELINED | pipelined | pipelined | batch |
| PIPELINED_FORCED | pipelined | pipelined | pipelined |
| BATCH | pipelined | batch | batch |
| BATCH_FORCED | batch | batch | batch |
理论上可以组合出8种模式,但是其余几种没有太大实际意义。